一、简介
贝叶斯分类是一类分类算法的总称,算法以贝叶斯定理为基础,所以称为贝叶斯分类。本文将首先介绍分类问题,对分类问题进行一个正式的定义。然后,介绍贝叶斯分类算法的基础——贝叶斯定理。最后,通过实例讨论贝叶斯分类中最简单的一种:朴素贝叶斯分类。
二、分类问题介绍
分类,顾名思义,就是把集合分出类别来,比如人类可以分为黄种人、白种人、黑种人。
在数学方面可以做如下定义:
已知集合:
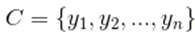
和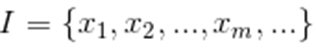
确定映射规则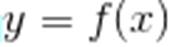
使得任意有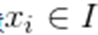
且仅有一个
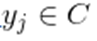
使得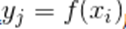
成立
其中C叫做类别集合,其中每一个元素是一个类别,而I叫做项集合,其中每一个元素是一个待分类项,f叫做分类器。分类算法的任务就是构造分类器f。
值得注意的是,分类问题常常采用经验性方法构造映射规则,及一般情况下的分类问题缺少足够的信息来构造百分百正确的映射规则,而是通过对经验数据的学习从而实现一定概率意义上的正确的分类,因此从训练出的分类器并不是一定能准确地将每个待分类项映射到其分类,分类器的质量与分类器构造方法、待分类数据的特性以及数据样本数量等诸多因素相关。
朴素贝叶斯算法前提说明
朴素贝叶斯算法成立的前提:各属性之间相互独立。当数据集满足这种独立性假设时,分类的准确度较高,否则可能较低。
贝叶斯定理理论基础
贝叶斯定理是关于随机事件(或边缘概率)的一则定理。这个定理解决了现实生活里经常遇到的问题:已知某条件概率,如何得到两个事件交换后的概率,也就是在已知P(A|B)的情况下如何求得P(B|A)
贝叶斯定理之所以有用,是因为我们在生活中经常遇到这种情况:我们可以很容易直接得出P(A|B),P(B|A)则很难直接得出,但我们更关心P(B|A),贝叶斯定理就为我们打通从P(A|B)获得P(B|A)的道路。
下面不加证明地直接给出贝叶斯定理:
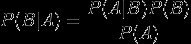
朴素贝叶斯分类的原理和流程
思想基础
朴素贝叶斯的思想基础:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。就比如说你在大街上见到一个黑哥们,你肯定首先认为他是个非洲人,但实际上黑人非洲、亚洲、美洲都有。但是非洲的黑人最多概率最大,所以你会认为他是个非洲人。
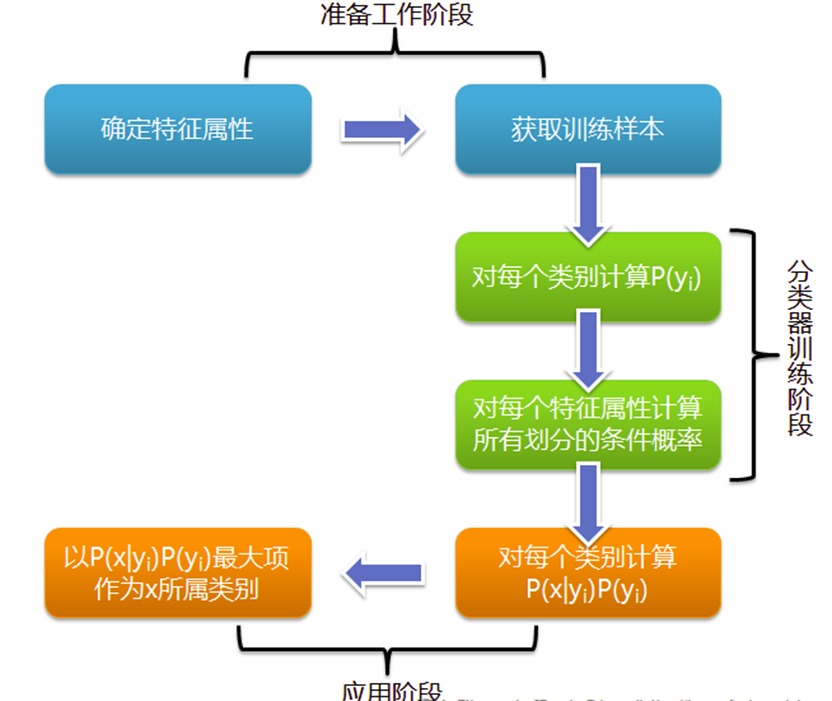
图示流程
正式定义
1.设 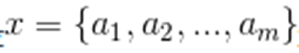 为一个待分类项,而每个a为x的一个特征属性
为一个待分类项,而每个a为x的一个特征属性
2.有类别集合
3.计算
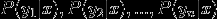
4.如果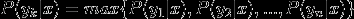
那么x∈yk
现在的关键就是如何计算第三步的各个条件概率。可以这样做:
1、找到一个已知分类的待分类项集合,这个集合叫做训练样本集。
2、统计得到在各类别下各个特征属性的条件概率估计。即:
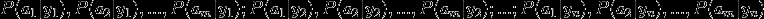
3、如果各个特征属性是条件独立的,则根据贝叶斯定理有如下推导: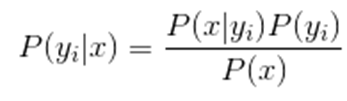
因为分母对所有的类别为常数,因此我们将分子最大化即可。又因为各特征属性是条件独立的,所以有:
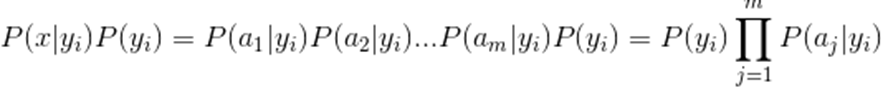
可以看到,整个朴素贝叶斯分类分为三个阶段:
第一阶段——准备工作阶段,这个阶段的任务是为朴素贝叶斯分类做必要的准备,主要工作是根据具体情况确定特征属性,并对每个特征属性进行适当划分,然后由人工对一部分待分类项进行分类,形成训练样本集合。这一阶段的输入是所有待分类数据,输出是特征属性和训练样本。这一阶段是整个朴素贝叶斯分类中唯一需要人工完成的阶段,其质量对整个过程将有重要影响,分类器的质量很大程度上由特征属性、特征属性划分及训练样本质量决定。
第二阶段——分类器训练阶段,这个阶段的任务就是生成分类器,主要工作是计算每个类别在训练样本中的出现频率及每个特征属性划分对每个类别的条件概率估计,并将结果记录。其输入是特征属性和训练样本,输出是分类器。这一阶段是机械性阶段,根据前面讨论的公式可以由程序自动计算完成。
第三阶段——应用阶段。这个阶段的任务是使用分类器对待分类项进行分类,其输入是分类器和待分类项,输出是待分类项与类别的映射关系。这一阶段也是机械性阶段,由程序完成。
特殊情况
这一节讨论P(a|y)的估计。
由上文看出,计算各个划分的条件概率P(a|y)是朴素贝叶斯分类的关键性步骤,当特征属性为离散值时,只要很方便的统计训练样本中各个划分在每个类别中出现的频率即可用来估计P(a|y),下面重点讨论特征属性是连续值的情况。
当特征属性为连续值时,通常假定其值服从高斯分布(也称正态分布)。即:
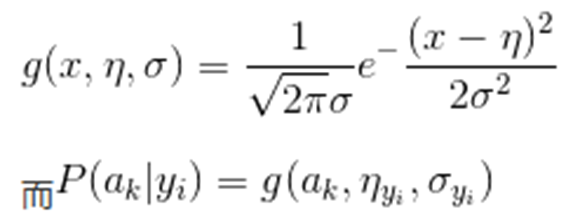
因此只要计算出训练样本中各个类别中此特征项划分的各均值和标准差,代入上述公式即可得到需要的估计值。均值与标准差的计算在此不再赘述。
另一个需要讨论的问题就是当P(a|y)=0怎么办,当某个类别下某个特征项划分没有出现时,就是产生这种现象,这会令分类器质量大大降低。为了解决这个问题,我们引入Laplace校准,它的思想非常简单,就是对没类别下所有划分的计数加1,这样如果训练样本集数量充分大时,并不会对结果产生影响,并且解决了上述频率为0的尴尬局面。
实验:汽车估计数据集
一.数据描述:
n汽车评估数据集包含1728个数据,其中训练数据1350,测试数据 378个。每个数据包含6个属性,所有的数据分为4类:
ClassValues: unacc, acc,good, vgood
Attributes:
buying: vhigh,high, med, low.
maint: vhigh,high, med, low.
doors:2, 3, 4, 5more.
persons:2, 4, more.
lug_boot:small, med, big.
safety:low, med, high.
未校准:

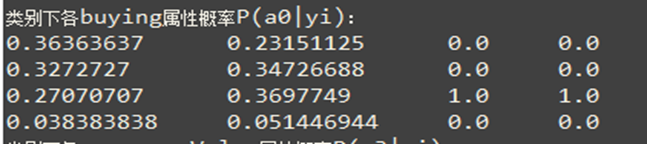
校准后:


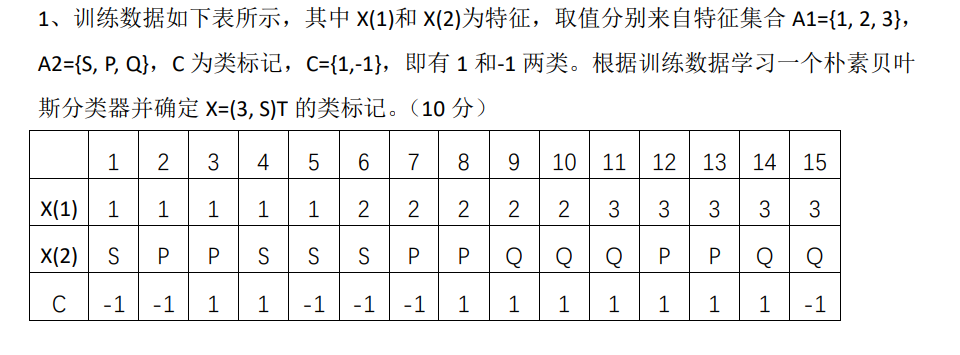
例题