学习概述
机器学习
机器可以自动”学习”的算法,即从数据中自动分析获得规律,并利用规律对未知数据进行预测的算法。
学习的反馈类型
无监督学习
不提供任何的显示反馈,比如:KNN聚类算法
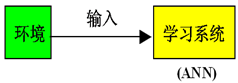
监督学习
提供“输入-输出”对,学习从输入到输出的映射函数。比如:贝叶斯网络,人工神经网络,决策树
半监督学习
提供少量的“输入-输出”对,大部分样本未标注。基于图的学习算法。
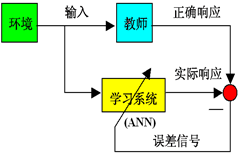
监督学习
监督学习的任务是:
1.给定由N个“输入-输出”对样例组成的训练集从给定的训练数据集中学习出一个函数(模型参数)
2.当新的数据到来时,可以根据这个函数预测结果
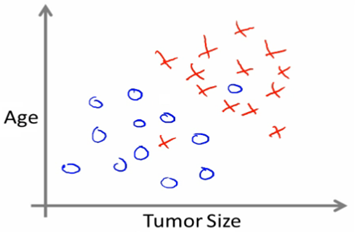
分类与回归
分类问题的主要目的是预测分类标签,标签来自预定义的可选列表。分类问题可分为二分类和多分类。
比如邮件系统,对于垃圾邮件的识别就是一个分类问题。
回归任务的目标是预测一个连续值。
例如,根据教育水平、年龄和居住地来预测一个人的年收入,预测的结果是一个金额数值。

K-折交叉验证
思想:每个样本既作为训练数据,又作为测试数据
将数据分成k个相等的子集
执行k轮次学习,每一轮1/k个数据作为测试数据,其他作为训练数据
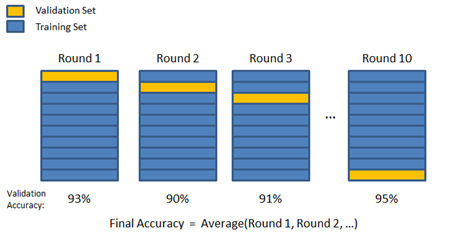
精度增加伴随着代价增加
过拟合/欠拟合
过拟合
拟合模型时,过分关注训练集的细节,训练集学习得到的目标函数在训练集上性能很好,在测试集上性能不高。
训练出的模型太复杂,不能泛化到新数据上的模型就叫做过拟合。
其实就是训练次数过多导致找到了太多只适用于训练集的特征,过于细化所以不能通用。
欠拟合
相反,如果模型过于简单,那么就可能无法抓住数据的全部内容以及数据中的变化。甚至可能模型在训练集上的表现也很差。也就是没要找到特征。
如何避免过拟合
- Early stopping (适当的stoppingcriterion):
Early stopping便是一种迭代次数截断的方法来防止过拟
合的方法,即在模型对训练数据集迭代收敛之前停止迭代
来防止过拟合
2) 数据集扩增 : 数据机扩增即需要得到更多的符合要求
的数据,即和已有的数据是独立同分布的,或者近似独立
同分布的。一般方法有:从数据源头采集更多数据,复制
原有数据并加上随机噪声,重采样,根据当前数据集估计
数据分布参数,使用该分布产生更多数据等
3)正则化方法:一般有L1正则与L2正则等
4)Dropout:正则是通过在代价函数后面加上正则项来防
止模型过拟合的。而在神经网络中,有一种方法是通过修
改神经网络本身结构来实现的,其名为Dropout。
信息理论:熵
熵H(x):衡量数据集的纯度
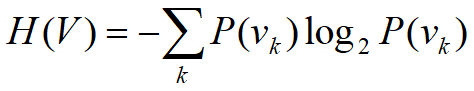
熵曲线
两个样本(P,N),p个正样本数,n个负样本数,p=9,n=5
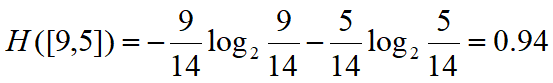
信息理论:属性选择
根据熵的定义,公平掷硬币的熵:
$$
H(Fair)=− (0.5log_20.5 +0.5 log_20.5 )= 1
$$
如果加载硬币,使之能掷出99%正面向上,则有
$$
H(Loaded)=− (0.99log_20.99+0. 01log_20.01) ≈0.08
$$
设布尔变量以q的概率为真,则可定义该变量的熵为:
$$
B(q)=− (q log_2q +(1-q)log_2(1-q) )
$$
因此
$$
H(Loaded)=B(0.99)≈0.08
$$
一个训练数据集包含p个正样本,n个负样本,则目标属性在整个样例集上的熵为:
$$
H(Goal)= B(𝑝/(𝑝+𝑛))
$$
一个属性A的取值为A1,A2,…,Av,根据属性A的取值将训练数据集E分成E1,E2,…Ev,每个子集Ei有pi个正例和ni个反例,则选择属性A后,剩余的期望熵值为:
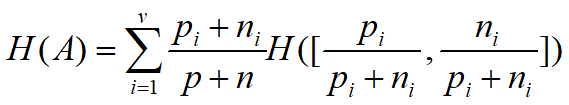
属性A的信息收益是熵的期望减少,即原有的熵值-属性A分裂后的熵值:
$$
Gain(A)= B(𝑝/(𝑝+𝑛)) - H(A)
$$
$$
Gain(Patrons)= 1−[2/12B(0/2)+4/12B(4/4)+6/12B(2/6)]≈0.541
$$
$$
Gain(Type)= 1−[2/12B(1/2)+2/12B(1/2)+4/12B(2/4)+4/12B(2/4)]=0
$$
$$
Gain(Patrons)>Gain(Type)
$$
选择信息收益最大的属性进行分裂
决策树剪枝
找到过度拟合的结点,删除该节点及其分支
如果一个节点是过度拟合的,则该结点不同属性之下所含正样本的比例与整个集合的比例大致相同,pk/(pk+nk)≈p/(p+n)
