图
图的物理实现
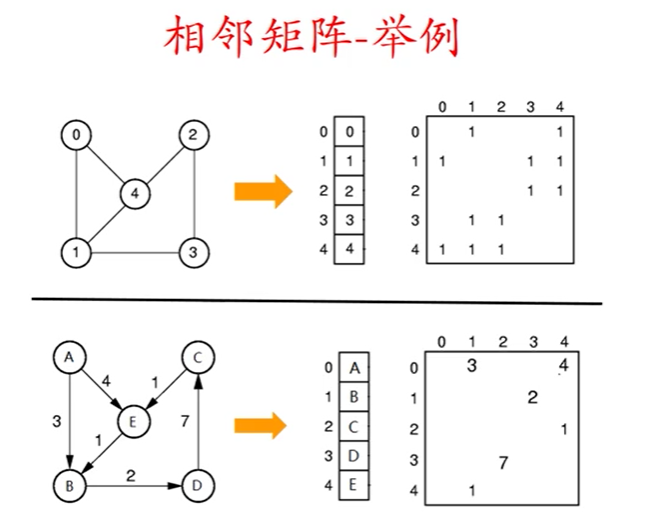
邻接矩阵(相邻矩阵)
图的相邻矩阵表示法
图的顶点元素是|V|的顺序表
图的相邻矩阵是一个|V|×|V|矩阵
如果从Vi到Vj存在一条边,则对第i行的第j个元素做标记,否则不做标记
如果矩阵中的元素要存储边的权值,那么矩阵的每个元素必须足够大(存储权值),或者存储一个指向权值存储位置的指针。
具体图如下:
特点分析
可以存储无向图或者有向图
相邻矩阵需要存储所有可能的边,不管这条边是否实际存在。
没有结构性开销,但是存在空间浪费
相邻矩阵的空间代价只与顶点的个数有关,为O(|V²|),图越密集空间效率越高。
基于相邻矩阵的图算法,必须查看它的所有可能的边,导致总时间代价为O(|V²|),所以相邻矩阵适合密集图的存储。
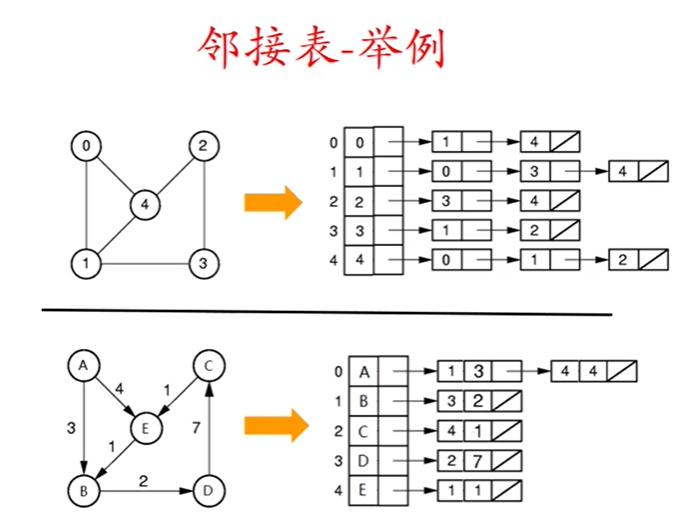
邻接表
邻接表表示法
邻接表是一个包含|V|个元素的顺序表
每个元素包含两个域,一个存储图的一个顶点信息,另一个是一个指针,指向该顶点的边构成的链表。
这个链表通过存储顶点的邻接点来表示对应的边,链表中的每个节点存储顶点的邻接点在顺序表中的位置。
如果要存储边的权值,则链表中的结点增加一个数据域(存储权值,或者存储一个指向权值存储位置的指针)
示意图
邻接表的特点分析
可以用于存储无向图和有向图
邻接表的空间代价与图中边的数目和顶点数目都有关系。每个顶点都要一个数组元素的位置(即使该顶点没有边),而每条边必须出现在其中某个顶点的链表中,所以邻接表的空间代价为O(|V|+|E|)
仅存储图中实际的边,没有空间浪费,但是存在结构性开销,图越稀疏,其空间效率越高
基于邻接表的图算法,需查看某个顶点和与其相邻的实际的边,其总时间代价为O(|V|+|E|),所以邻接表适合稀疏图。
逆邻接矩阵
其实就是邻接表反过来,邻接表记录的是以当前顶点为弧尾的边,那么逆邻接表就是记录以当前顶点为弧头的边。方便记录入度。
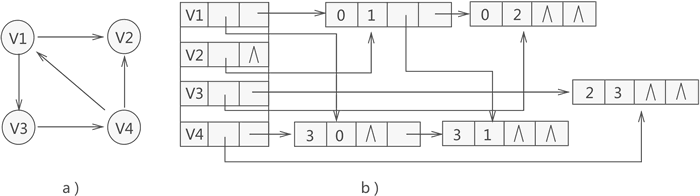
十字链表
和树的孩子兄弟表示法一样,十字链表法的每个弧结点都有两个指针域,分别指向弧头相同的下一条弧和弧尾相同的下一条弧。之所以用弧,是因为十字链表法分为两个部分:分别是顶点表和边表,顶点表里存放的是顶点结点,而边表中存放的是弧结点;它与邻接表不同之处在于它每个顶点后存的不再是顶点而是边。边里面就有两个结点。根据这两个节点方便我们统计有向图的出度和入度。
但是值得一提的是,十字链表法只适用于有向图:
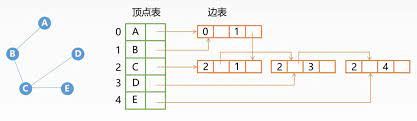
邻接多重表
邻接多重表用与十字链表法相同的存储结构来优化邻接表表示的无向图,无向图的空间复杂度是O(|V|+2|E|),邻接表里面的边多出来一倍,造成了空间上的浪费,所以就有了邻接多重表。
如下图所示,两个指针分别指向下一条依附于前面顶点的边;因此我们有多少条边才会有多少个边结点,空间复杂度也变成了O(|V|+|E|)
边集数组
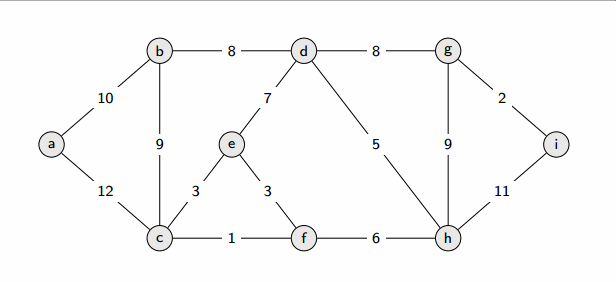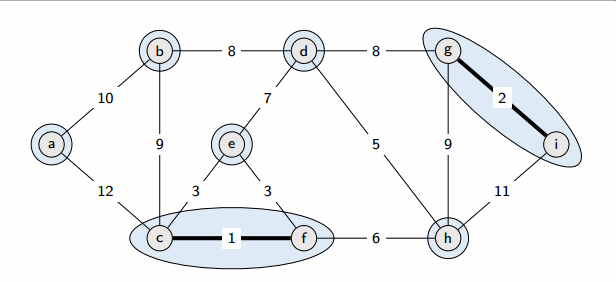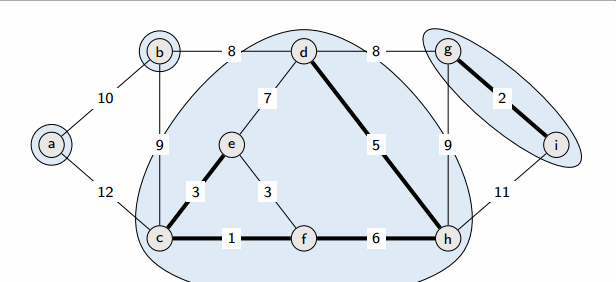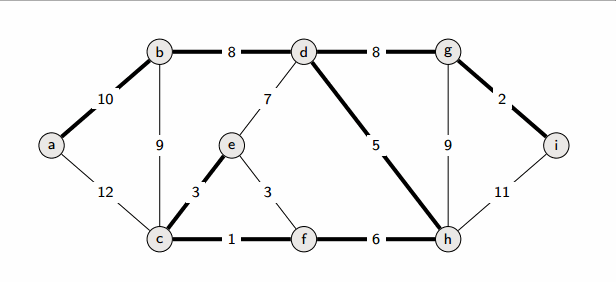
图的最小生成树
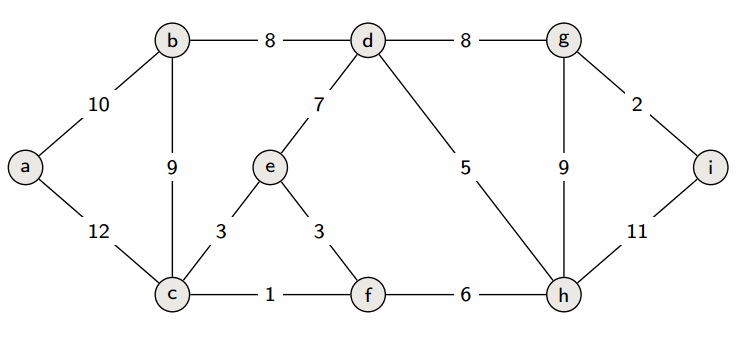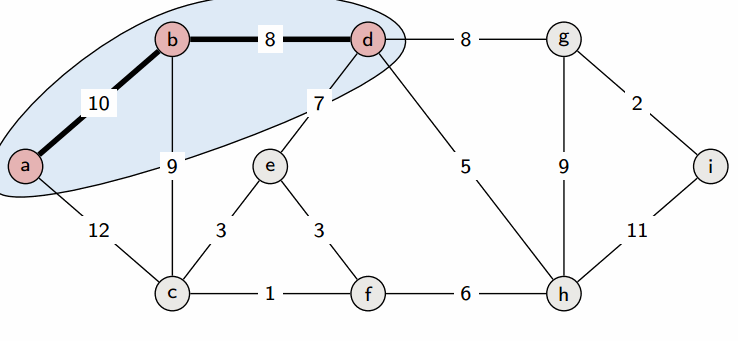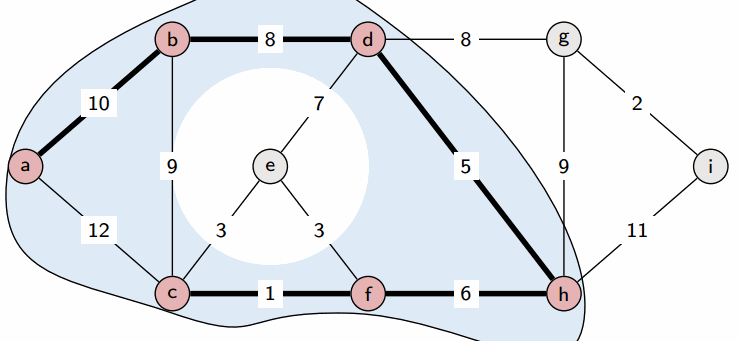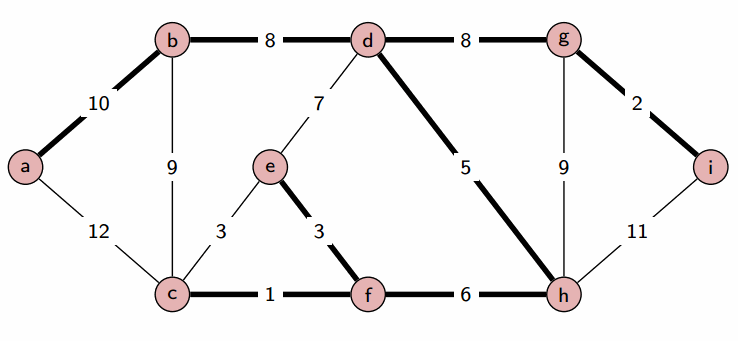
prim算法
prim算法和dijkstra算法很像,都是从一个点出发,开始找未联通但是距离最近的点,重复此操作知道形成极小连通图,更适合边稠密型的图;并且Prim算法的时间复杂为O(|E|^2)。
kruskal算法
kruskal算法则是一种边的算法,他通过找到代价最小的边开始,如果变量两边的结点都已经联通,那么就不计入,如果未联通则加入,直到生成连通图。所以kruskal更适合边稀疏图,因为使用并查集,所以时间复杂度为O(|E|log|E|)。